1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
|
/**
* @file centroid.cpp
* @author mango ([email protected])
* @brief Simd
* @version 0.1
* @date 2021-10-24
*
* @copyright Copyright (c) 2021
*
*/
#include <random>
#include <iostream>
#include <vector>
#include <chrono>
#include "pcl/point_cloud.h"
#include "pcl/point_types.h"
#include "pcl/common/centroid.h"
#include "opencv2/core/simd_intrinsics.hpp"
#include "omp.h"
#include "matplotlibcpp.h"
namespace plt = matplotlibcpp;
void GetCentroidSimd(pcl::PointCloud<pcl::PointXYZ>::ConstPtr cloud, pcl::PointXYZ& centroid)
{
if(cloud->empty()) {return;}
int count = cloud->size();
cv::v_float32 centroidx = cv::vx_setzero_f32();
cv::v_float32 centroidy = cv::vx_setzero_f32();
cv::v_float32 centroidz = cv::vx_setzero_f32();
int step = cv::v_float32::nlanes;
for (int i = 0; i < count; i += step)
{
//固定长方法
//cv::v_float32 vx(cloud->points[i].x, cloud->points[i + 1].x, cloud->points[i + 2].x, cloud->points[i + 3].x);
//cv::v_float32 vy(cloud->points[i].y, cloud->points[i + 1].y, cloud->points[i + 2].y, cloud->points[i + 3].y);
//cv::v_float32 vz(cloud->points[i].z, cloud->points[i + 1].z, cloud->points[i + 2].z, cloud->points[i + 3].z);
cv::v_float32 vx;
cv::v_float32 vy;
cv::v_float32 vz;
cv::v_float32 vs;//占位数据
cv::v_load_deinterleave(&cloud->points[i].x, vx, vy, vz, vs);
centroidx += vx;
centroidy += vy;
centroidz += vz;
}
centroid.x = cv::v_reduce_sum(centroidx);
centroid.y = cv::v_reduce_sum(centroidy);
centroid.z = cv::v_reduce_sum(centroidz);
for (size_t i = count - count % step; i < count; i++)
{
centroid.x += cloud->points[i].x;
centroid.y += cloud->points[i].y;
centroid.z += cloud->points[i].z;
}
centroid.x /= count;
centroid.y /= count;
centroid.z /= count;
}
void GetCentroidSimdWithOpenMP(pcl::PointCloud<pcl::PointXYZ>::ConstPtr cloud, pcl::PointXYZ& centroid)
{
if (cloud->empty()) { return; }
int count = cloud->size();
cv::v_float32x4 centroidx = cv::v_setzero_f32();
cv::v_float32x4 centroidy = cv::v_setzero_f32();
cv::v_float32x4 centroidz = cv::v_setzero_f32();
int step = cv::v_float32x4::nlanes;
//#pragma omp parallel for reduction(+:centroidx,centroidy,centroidz) : 错误,v_float32类型不可做reduction,下面手动reduction
//std::vector<cv::v_float32x4> centroidx_arr(4, cv::v_setzero_f32());
//std::vector<cv::v_float32x4> centroidy_arr(4, cv::v_setzero_f32());
//std::vector<cv::v_float32x4> centroidz_arr(4, cv::v_setzero_f32());
std::array<cv::v_float32x4, 4> centroidx_arr;
std::array<cv::v_float32x4, 4> centroidy_arr;
std::array<cv::v_float32x4, 4> centroidz_arr;
#pragma omp parallel for
for (int i = 0; i < count; i += step)
{
cv::v_float32x4 vx;
cv::v_float32x4 vy;
cv::v_float32x4 vz;
cv::v_float32x4 vs;//占位数据
cv::v_load_deinterleave(&cloud->points[i].x, vx, vy, vz, vs);
int id = omp_get_thread_num();
centroidx_arr[id] += vx;
centroidy_arr[id] += vy;
centroidz_arr[id] += vz;
}
//手动reduction
for (auto& a : centroidx_arr){ centroidx += a; }
for (auto& a : centroidy_arr){ centroidy += a; }
for (auto& a : centroidz_arr){ centroidz += a; }
centroid.x = cv::v_reduce_sum(centroidx);
centroid.y = cv::v_reduce_sum(centroidy);
centroid.z = cv::v_reduce_sum(centroidz);
for (size_t i = count - count % step; i < count; i++)
{
centroid.x += cloud->points[i].x;
centroid.y += cloud->points[i].y;
centroid.z += cloud->points[i].z;
}
centroid.x /= count;
centroid.y /= count;
centroid.z /= count;
}
void GetCentroidOpenMP(pcl::PointCloud<pcl::PointXYZ>::ConstPtr cloud, pcl::PointXYZ& centroid)
{
if (cloud->empty()) { return; }
int count = cloud->size();
float x_sum = 0;
float y_sum = 0;
float z_sum = 0;
#pragma omp parallel for reduction(+:x_sum,y_sum,z_sum)
for (int i = 0; i < count; i++)
{
x_sum += cloud->points[i].x;
y_sum += cloud->points[i].y;
z_sum += cloud->points[i].z;
}
centroid.x = x_sum /count;
centroid.y = y_sum /count;
centroid.z = z_sum /count;
}
int main(int argc, char** argv)
{
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<float> dist(-1000.0f, 1000.0f);
std::vector<double> x;
std::vector<double> none_y;
std::vector<double> simd_y;
std::vector<double> openmp_y;
std::vector<double> simd_openmp_y;
for (size_t p = 1; p < 8; p++)
{
size_t point_size = std::pow(10, p);
double none_t = 0;
double simd_t = 0;
double openmp_t = 0;
double simd_openmp_t = 0;
size_t test_count = 10;
for (size_t k = 0; k < test_count; k++)
{
cloud->clear();
for (size_t i = 0; i < point_size; i++)
{
cloud->push_back(pcl::PointXYZ(dist(gen), dist(gen), dist(gen)));
}
pcl::PointXYZ centroid;
auto t0 = std::chrono::system_clock::now();
pcl::computeCentroid(*cloud, centroid);
auto t1 = std::chrono::system_clock::now();
GetCentroidSimd(cloud, centroid);
auto t2 = std::chrono::system_clock::now();
GetCentroidOpenMP(cloud, centroid);
auto t3 = std::chrono::system_clock::now();
GetCentroidSimdWithOpenMP(cloud, centroid);
auto t4 = std::chrono::system_clock::now();
none_t += std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0).count();
simd_t += std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
openmp_t += std::chrono::duration_cast<std::chrono::milliseconds>(t3 - t2).count();
simd_openmp_t += std::chrono::duration_cast<std::chrono::milliseconds>(t4 - t3).count();
}
std::cout << "none_t = " << none_t / test_count << " ms." << std::endl;
std::cout << "simd_t = " << simd_t / test_count << " ms." << std::endl;
std::cout << "openmp_t = " << openmp_t / test_count << " ms." << std::endl;
std::cout << "simd_openmp_t = " << simd_openmp_t / test_count << " ms." << std::endl;
x.push_back(double(point_size));
none_y.push_back(none_t);
simd_y.push_back(simd_t);
openmp_y.push_back(openmp_t);
simd_openmp_y.push_back(simd_openmp_t);
}
std::map<std::string, std::string> pcl_result;
std::map<std::string, std::string> simd_result;
std::map<std::string, std::string> openmp_result;
std::map<std::string, std::string> simd_openmp_result;
pcl_result.insert(std::pair<std::string, std::string>("color", "red"));
pcl_result.insert(std::pair<std::string, std::string>("label", "pcl-default"));
simd_result.insert(std::pair<std::string, std::string>("color", "green"));
simd_result.insert(std::pair<std::string, std::string>("label", "simd-optimization"));
openmp_result.insert(std::pair<std::string, std::string>("color", "blue"));
openmp_result.insert(std::pair<std::string, std::string>("label", "openmp-optimization"));
simd_openmp_result.insert(std::pair<std::string, std::string>("color", "black"));
simd_openmp_result.insert(std::pair<std::string, std::string>("label", "simd&openmp-optimization"));
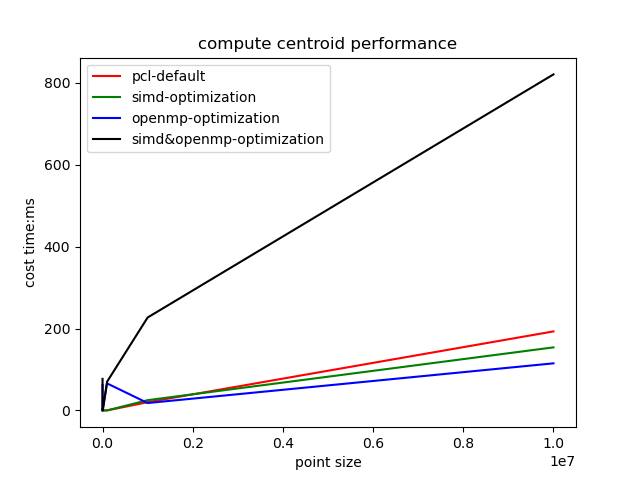
plt::plot(x, none_y, pcl_result);
plt::plot(x, simd_y, simd_result);
plt::plot(x, openmp_y, openmp_result);
plt::plot(x, simd_openmp_y, simd_openmp_result);
plt::xlabel("point size");
plt::ylabel("cost time:ms");
plt::legend();
plt::title("compute centroid performance");
plt::show();
return 0;
}
|