OpenCV自身是使用了许多优化技巧的,比如在多线程并行优化、simd指令集优化、基于OpenCL优化等等。但是官方默认编译的OpenCV库文件并未全部显示开启了这些优化选项,也就说默认编译的版本并非是所有优化选项都开启了。所以往往可以按照需求自行编译OpenCV,开启优化选项往往可以获得比官方默认版本更高的性能。自行编译的OpenCV建议注意考虑选择以下几个选项:
gpu
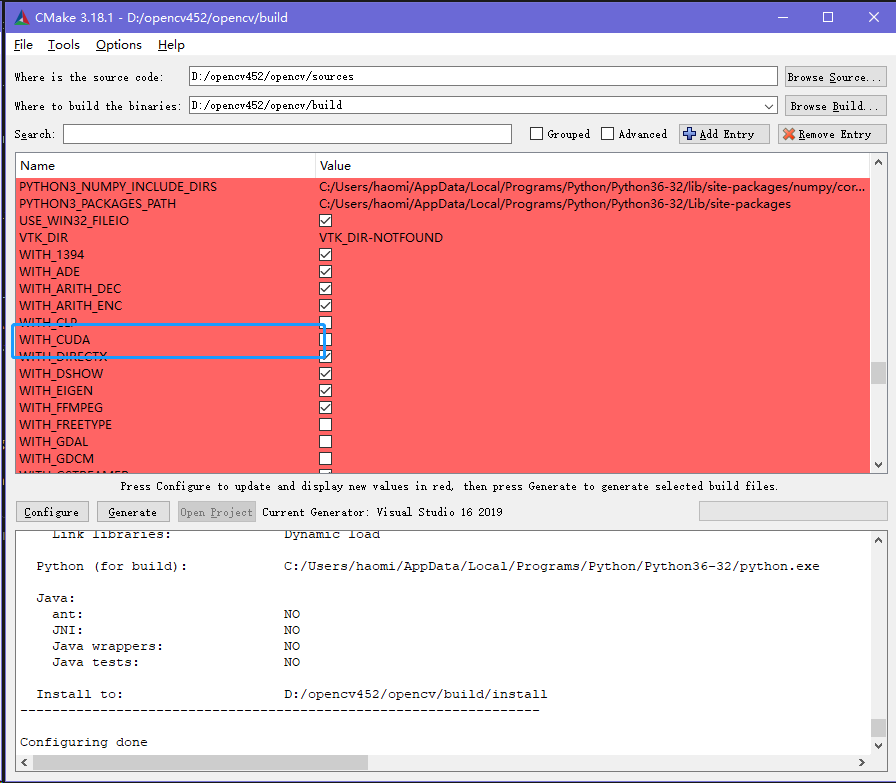
如果程序的目标运行平台是有英伟达显卡的,建议选择结合cuda编译OpenCV,并且在开发过程中可以选择gpu版本的功能函数。gpu在图像处理中比cpu具有更强的算力,在OpenCV中尤其是视频运动目标跟踪和深度学习模块中提升明显。
simd指令集
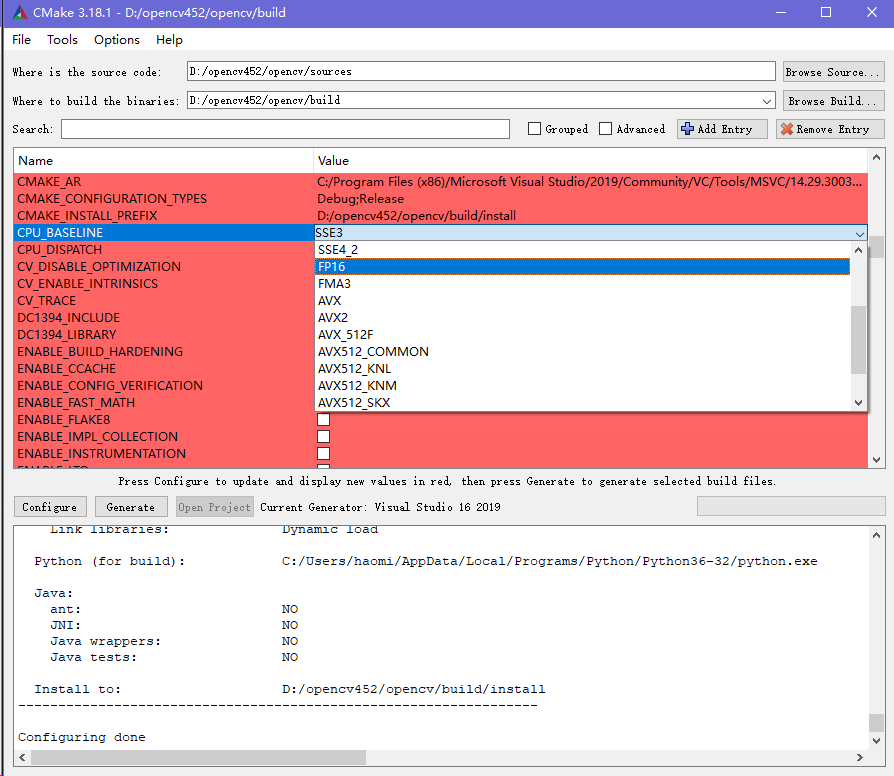
OpenCV大部分的功能函数在编写的时候都采用了simd指令集优化技术,尤其是在OpenCV4.x版本后采用了universal intrinsics统一的simd架构后更是完成了pc的x86平台(sse、avx等)、移动设备的arm平台(neon)以及浏览器的wasm平台的覆盖,据说rise-v的可变长simd支持也在路上。Simd可以实现单条指令一次运算多个数据,可以极大地提升程序性能。这么强的优化技术OpenCV默认是开启的,但是值得注意的是simd有不同的标准,比如pc的x86平台OpenCV默认选择的simd优化基准是sse,除了sse外OpenCV还支持了后续发布的avx、avx2、avx512的simd指令集基准。sse的单指令数据位宽是128,而avx与avx512的位宽分别为256与512,也就说单条指令理论上avx与avx512的优化相比sse可以进一步提升巨大的性能。所以在编译的时候可以根据你的cpu所支持的simd指令集选择更高的指令集优化,使用cpu-z软件可以查看电脑cpu所支持的指令集。在编译OpenCV的时候,CMake选择Simd指令集的额选项是CPU_BASELINE。OpenCV的SIMD统一框架简单使用方法如下:
|
|
具体的使用方法可以芒果之前的系列笔记:
官方默认的SIMD优化级别默认选项是SSE3,仅支持单条指令处理128bit的数据,现在绝大部分的pc处理器都已经支持avx2级别的simd优化,编译的时候选中avx2可以获取更高的性能提升。甚至如果目标机器支持avx512级别优化,也可以选择avx512级别编译以获取最大化的性能提升。
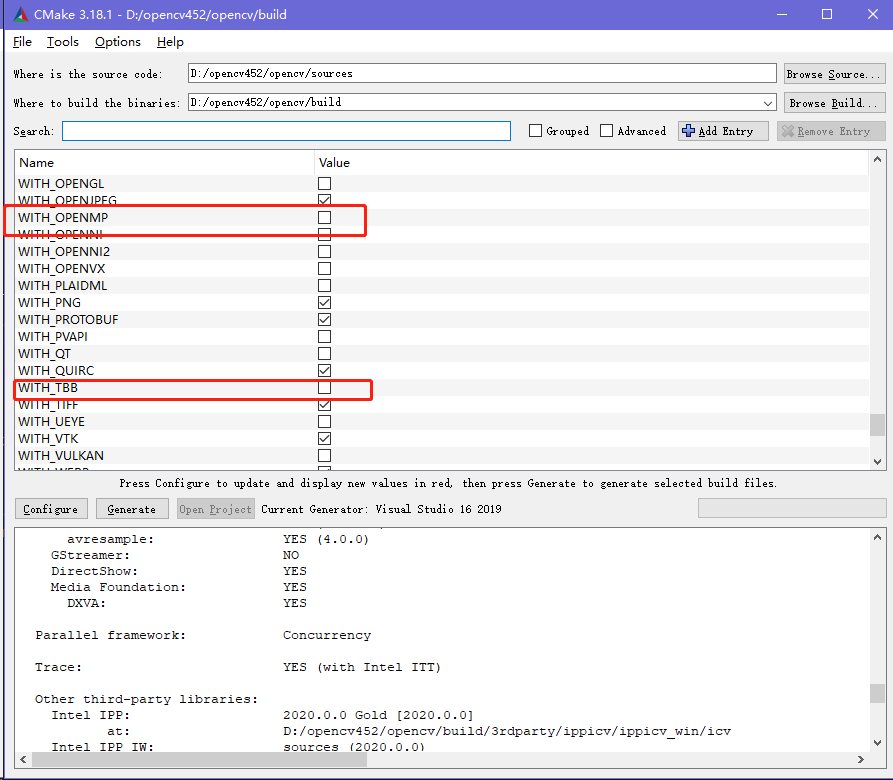
OpenMP或者TBB并行
提高OpenCV运行效率的另一个方法是通过多线程并行,OpenCV中许多算法的实现都基于并行做了相应的优化。其中大部分的并行处理都是采用OpenCV内置实现的for循环并行框架parallel_for, parallel_for框架针对
- intel的tbb
- C= Parallel C/C++ Programming Language Extension,一个第三方库
- OpenMP
- Apple的GCD
- Windows的concurrency,包括windows和windows-RT
- Linux平台下的pthread
其中再对应平台默认编译的会选择默认平台的多线程支持,比如官方的windows平台的安装包默认是使用微软提供的多线程框架。以使用经验看,手动明确选择使用OpenMP或者tbb做并行框架的后端可以获得更好的性能提升,主流编译器都默认支持OpenMP,勾选后直接可以编译。tbb相对麻烦一点点,由于tbb是以第三方库的实现方式,勾选TBB为并行框架后CMake后台会自动下载TBB源码进行编译和连接,使得编译过程会增加一定时间。推荐优先选择TBB,在网络不好的情况下,下载TBB不方便就选择OpenMP。因为在一些性能对比评测过程中,TBB相比OpenMP占据一定的优势。
本文由芒果浩明发布,转载请注明出处。 本文链接:https://blog.mangoeffect.net/opencv/optimization-methods-in-opencv-2.html
