物体分割(Object Segment)
物体分割属于图像理解的范畴,但图像理解包含众多,如包含着图像分类、物体检测、语义分割和实例分割等具体的问题。要想区分这些概念,就需要弄清楚每个问题具体研究什么,或者说对于图像的处理这个几个方式具体如何,目的又是得到什么效果。
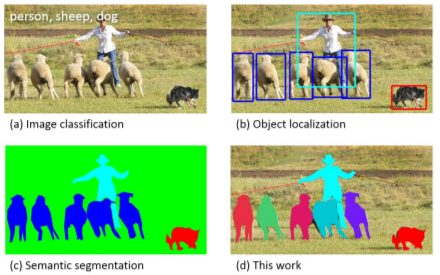
图像分类(Image Classification)
The task of object classification requires binary labels indicating whether objects are present in an image;
对象的分类任务需要二进制的标签(0、1)以指示目标是否存在图像之中。即任务需要对出现在图像中的物体做标注,例如有1000个物体类,在对于一幅图中的所有物体来说,某个物体只有两种结果,要么在图像里面,要么不在。任务可以实现的作用:输入一幅测试图片,输出该图片中物体类别的候选集。
物体检测(Object Detection)
Detecting an object entails both stating that an object belonging to a specified class is present, and localizing it in the image. The location of an object is typically represented by a bounding box
检测对象同时需要声明属于指定类的对象出现在图像之中。物体的位置对象通常由边界框表示。即这个任务要解决两个问题,一是需要判断某个特定类别的物体是否出现在该图像之中,二是需要对该物体定位,位置的表示通常使用边界框表示,即需要把检测到物体圈出来。任务可以实现的作用:输入一幅图测试图片,输出检测到物体的类别和位置。
语义分割/语义标注(Semantic Segmentation/Semantic Scene Labelig)
The task of labeling semantic objects in a scene requires that each pixel of an image be labeled as belonging to a category, such as sky, chair, floor, street, etc. In contrast to the detection task, individual instances of objects do not need to be segmented.
在场景中标注语义对象的任务要求将图像的每个像素标记为属于类别, 如天空、椅子、地板、街道等。与检测任务不同的是, 不需要对对象的各个实例进行区分。可以这么理解,语义分割/语义标注便是像素级的分类,对输入的图像的每一个像素点进行划分,属于同一类别物体的像素点为同一颜色,背景一般设为黑色。任务可以实现的作用:输入一幅测试图像,输出同类物体所在区域
实例分割(Instance Segmentation)
Our final stage is the laborious task of segmenting each object instance,
我们的最后阶段是区分每个对象实例的艰巨任务。可见,实例分割是语义分割的更进一步,对于图像中每个物体都要进行区分和标注。
参考文献
Microsoft COCO: Common Objects in Context.
本文由芒果浩明发布,转载请注明来源。 本文链接:https://blog.mangoeffect.net/opencv/object-detection-and-segment-4-task.html
